🧪 Test and evaluate MCP Servers with LLMs
Test how well LLM agents use your MCP tools, compare different models, and track quality over time with automated testing and detailed reports.
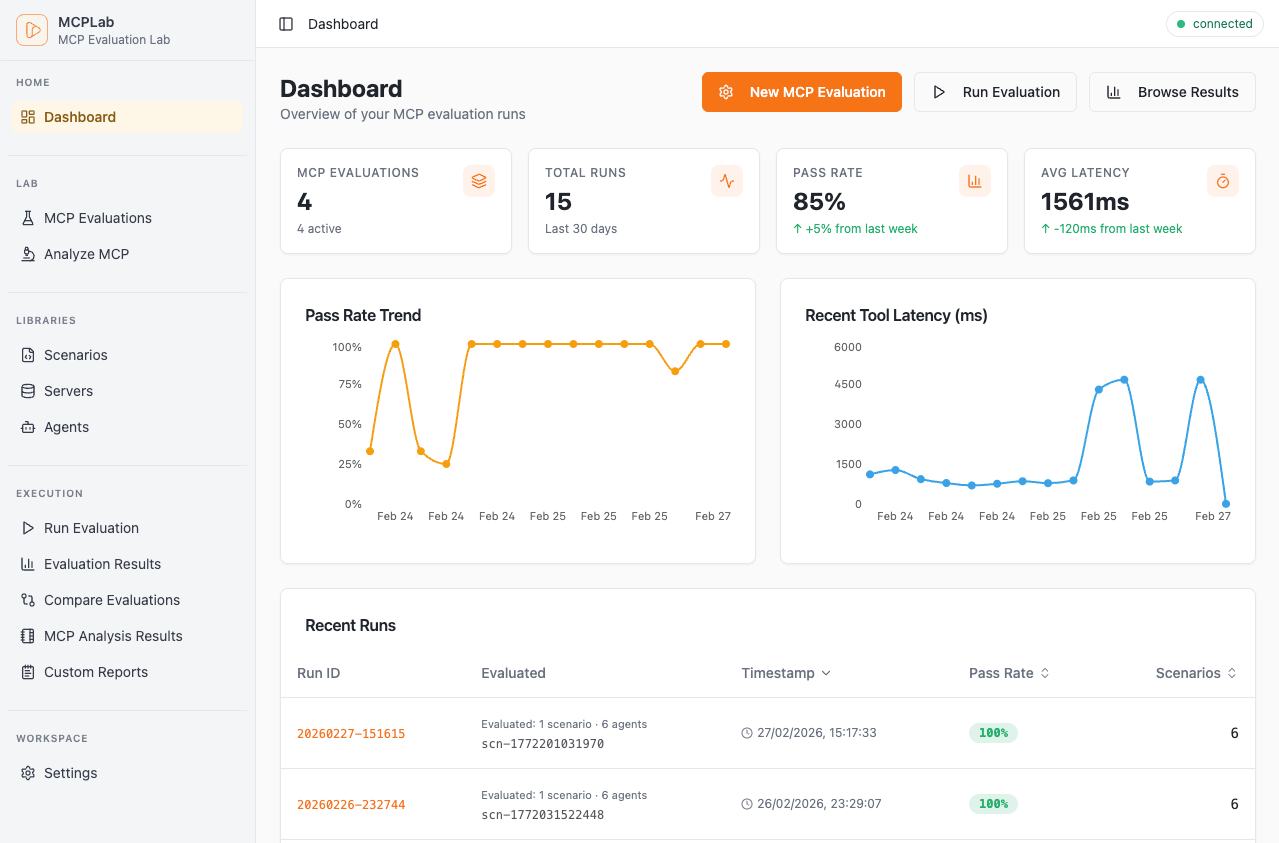
See It in Action
Rich visual reports, detailed traces, and interactive dashboards.
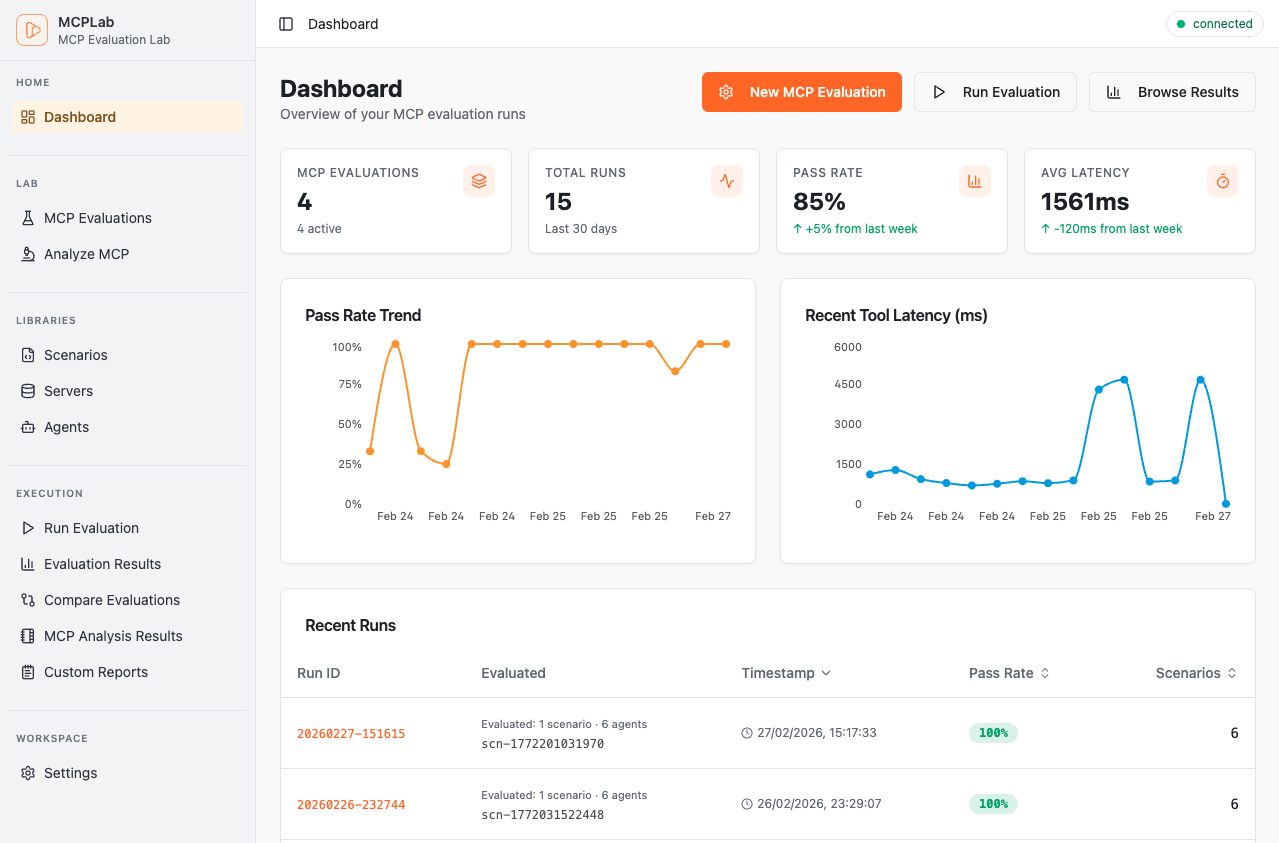
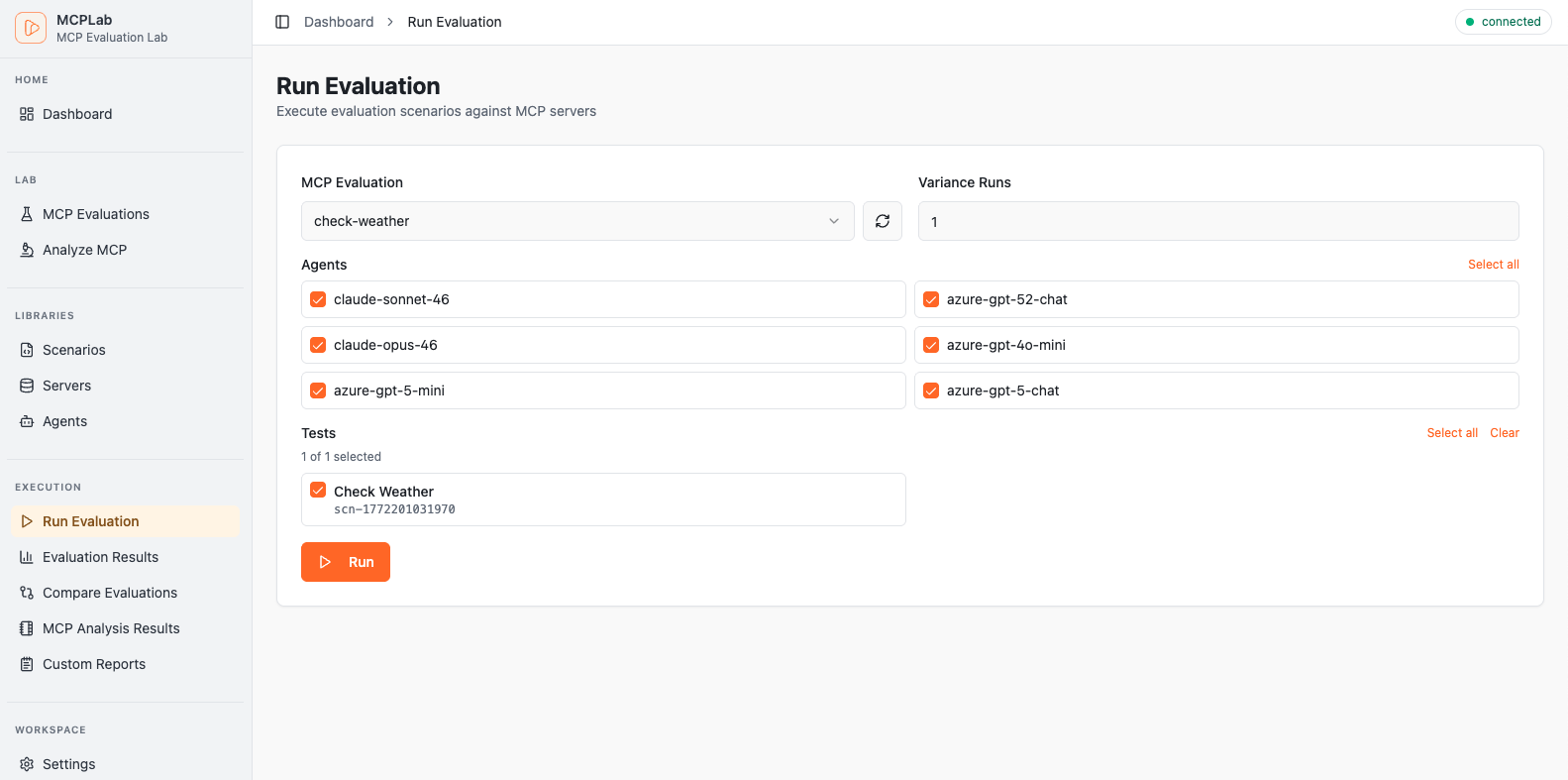
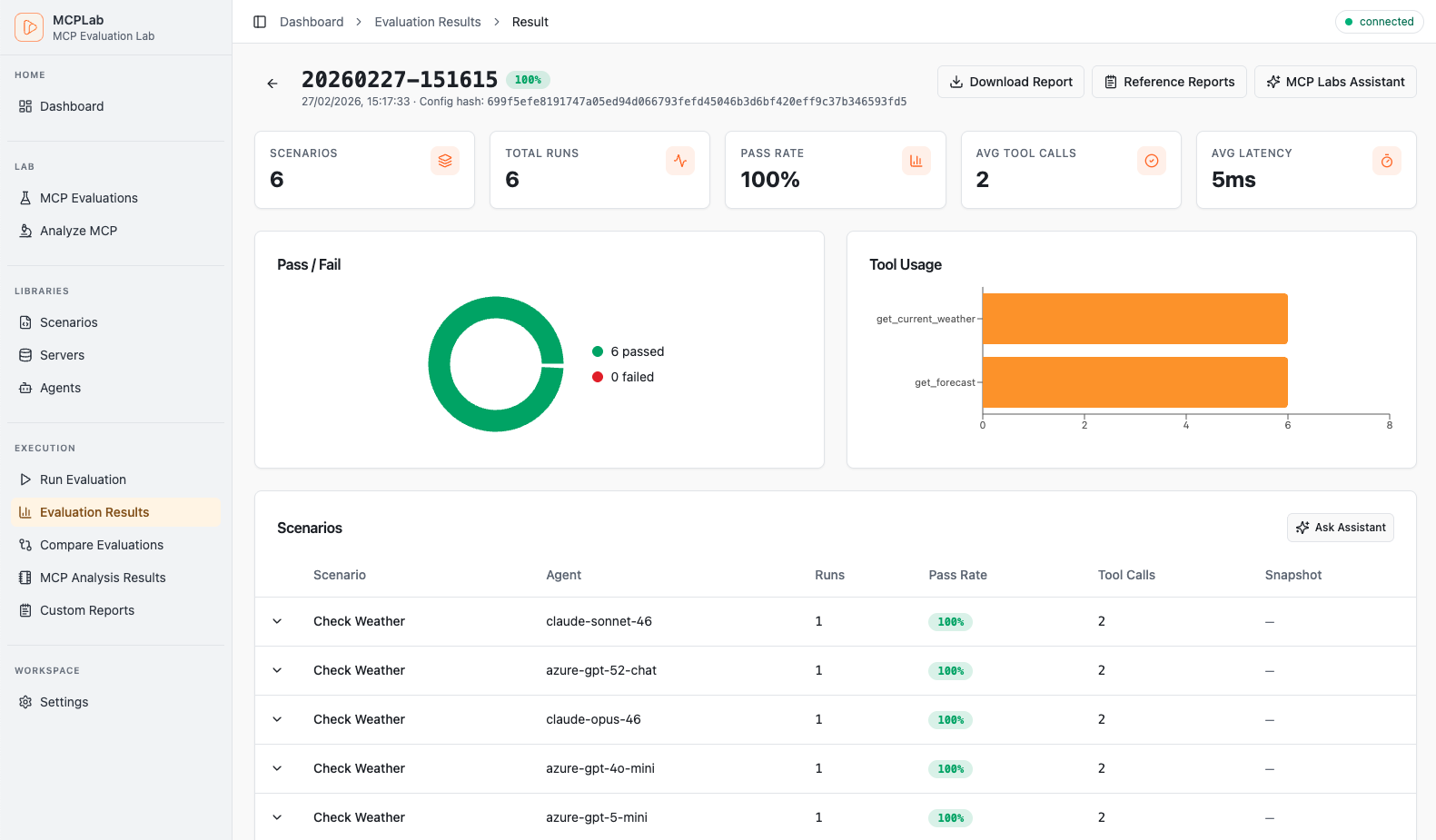
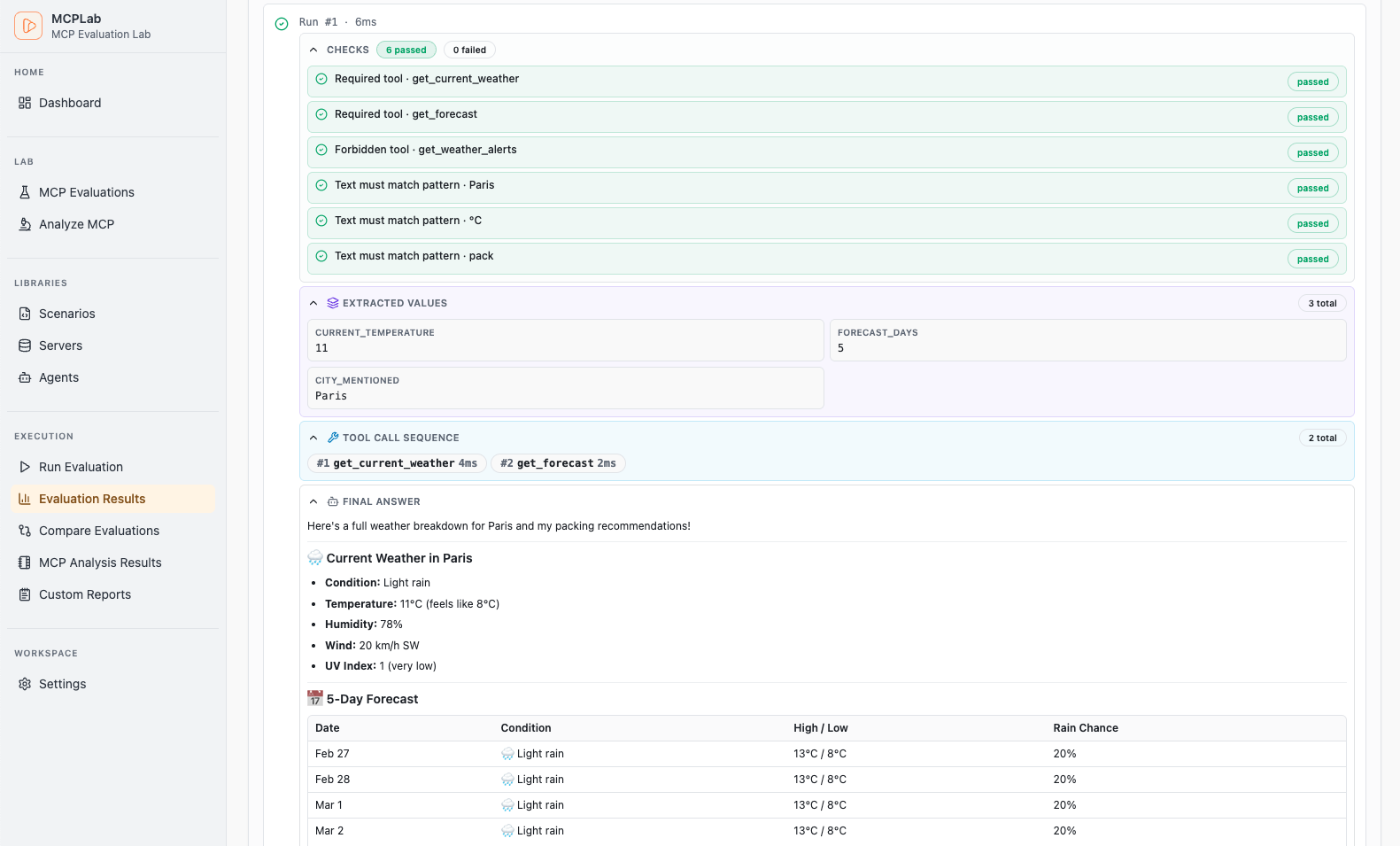
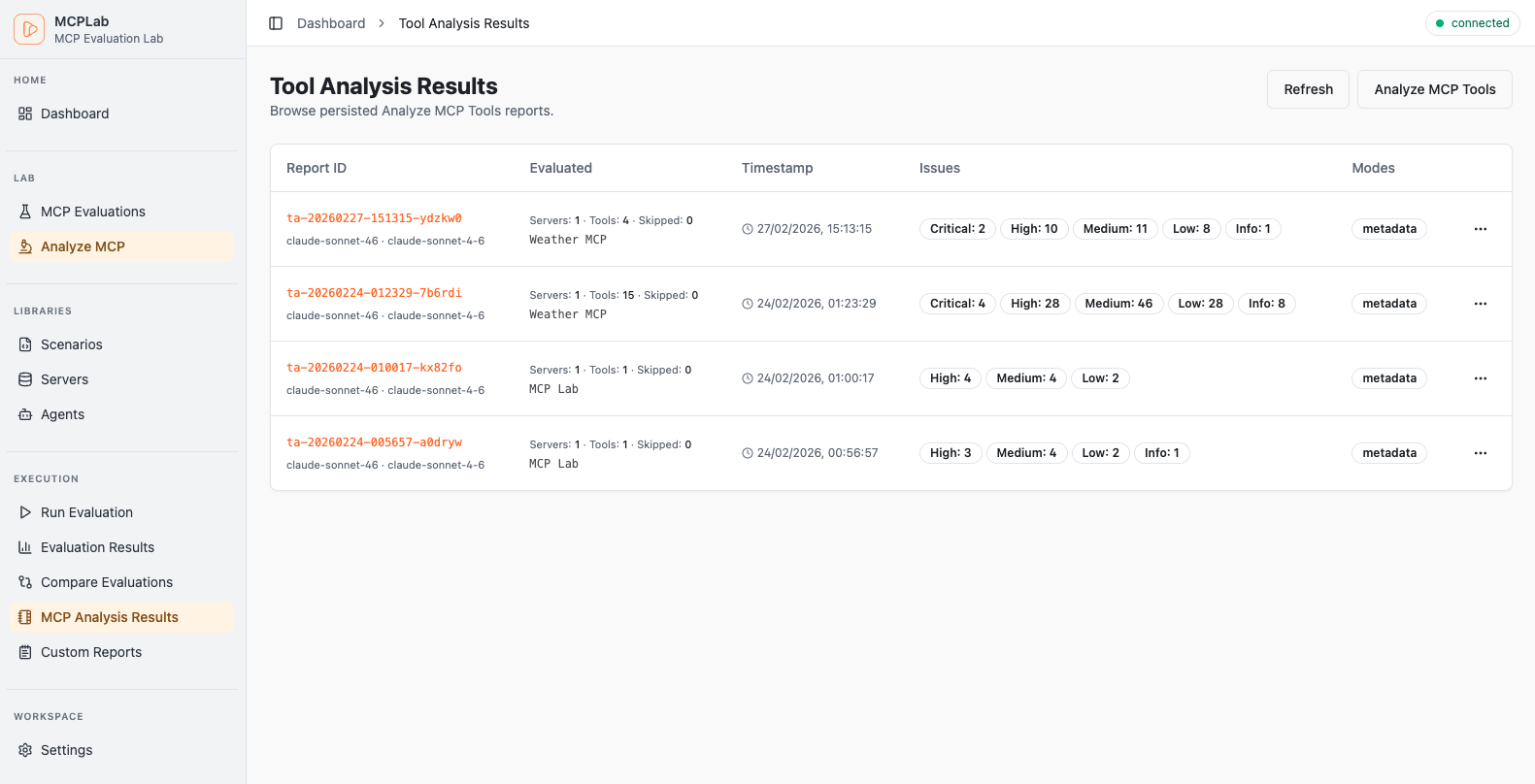
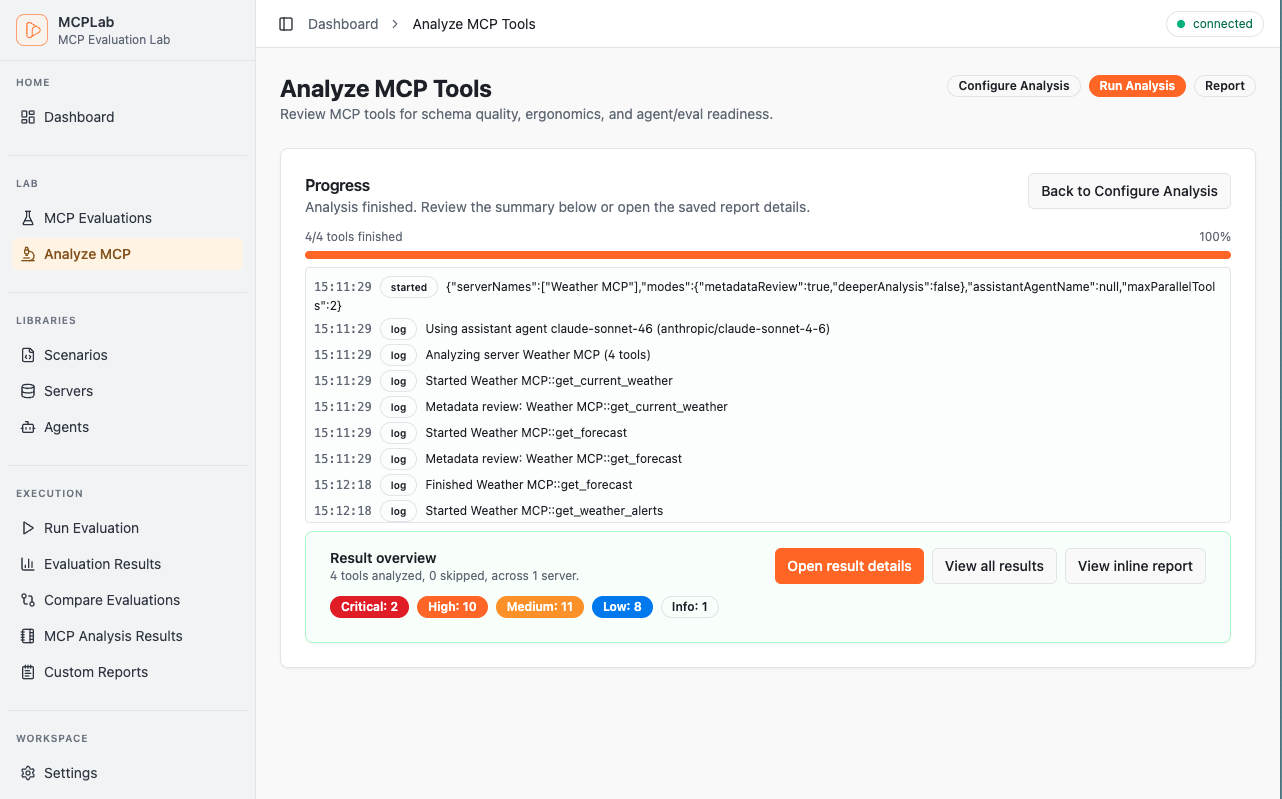
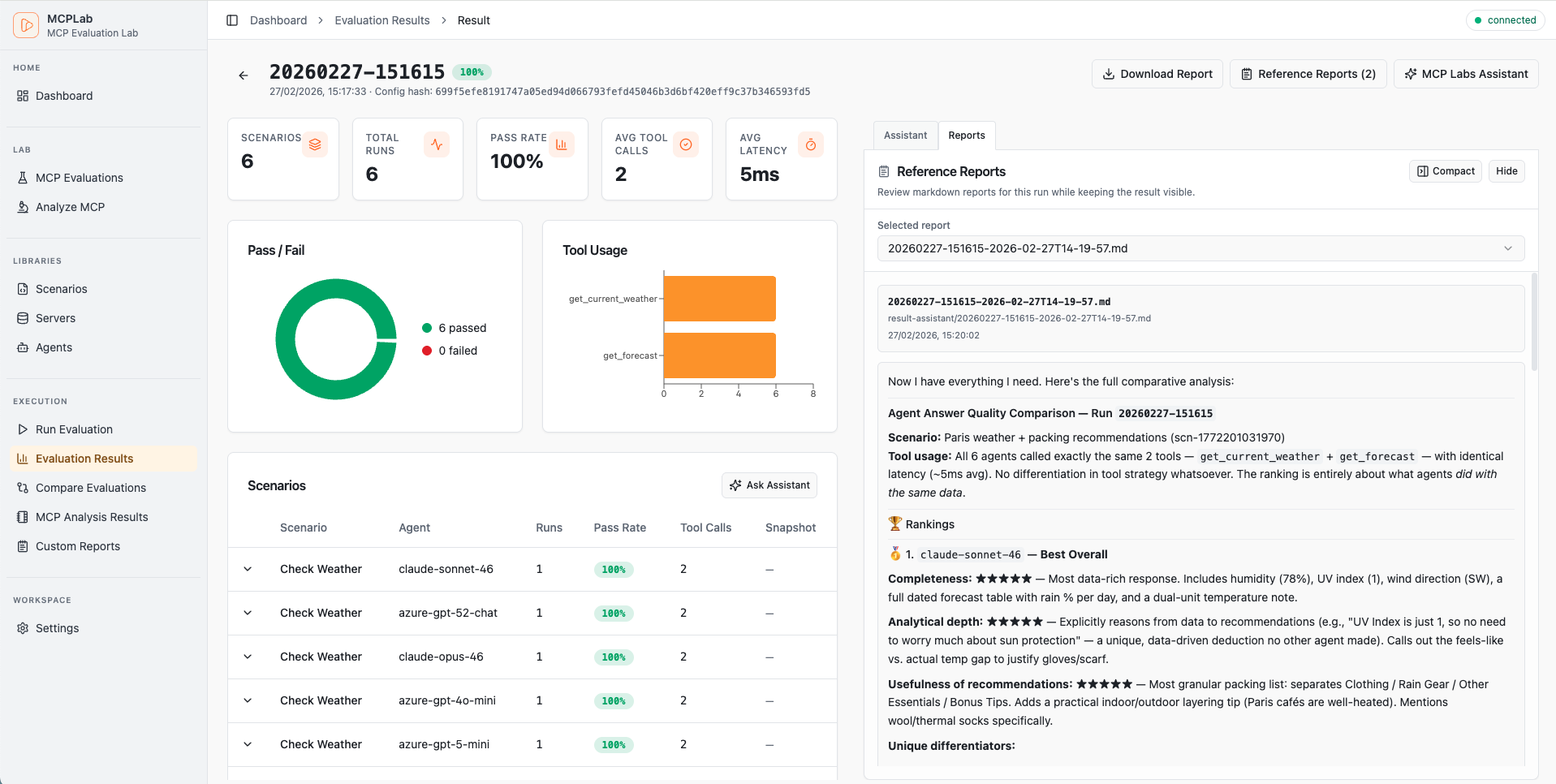
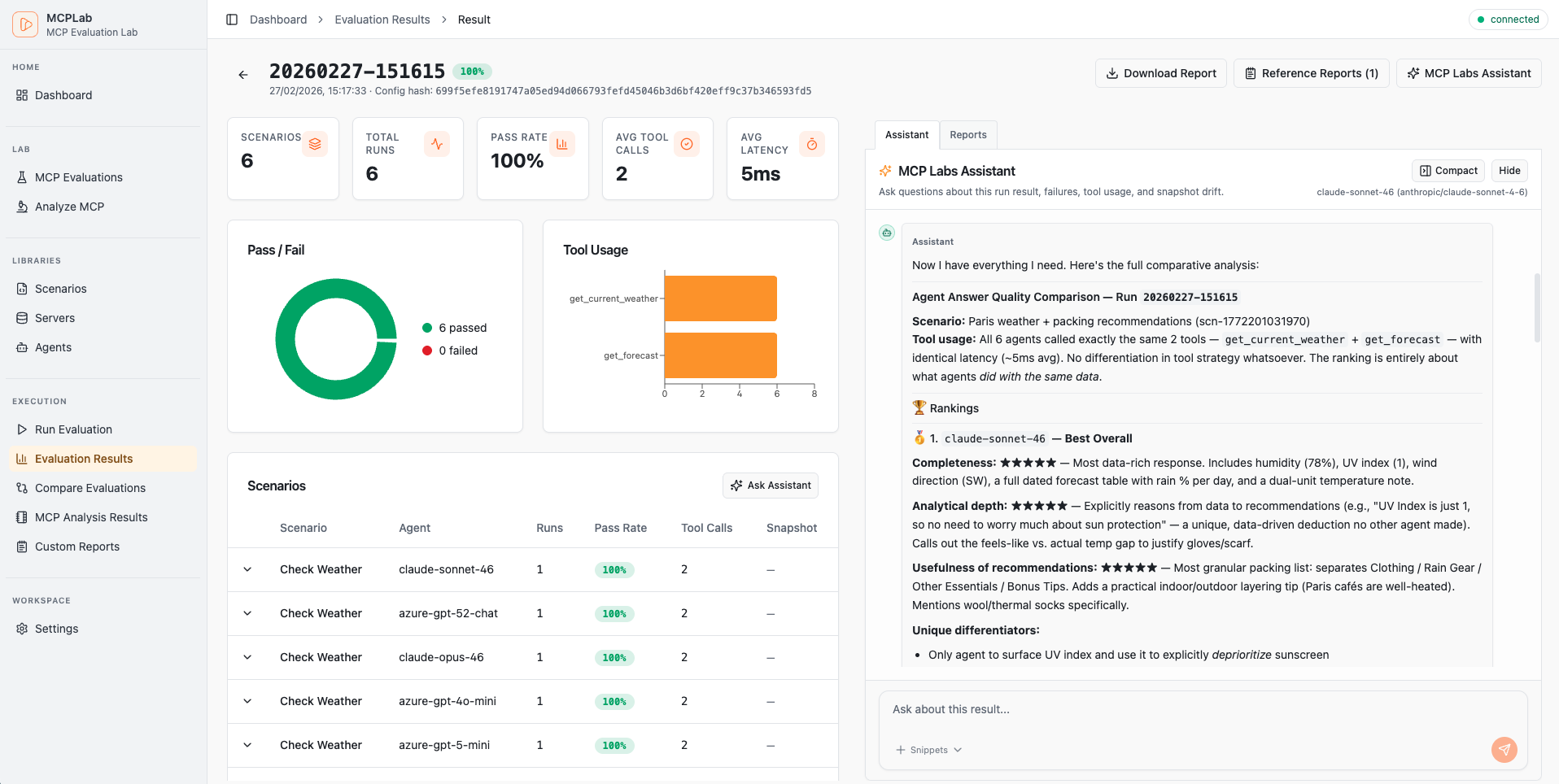
Track pass rates, latency trends and recent runs at a glance.
Core Capabilities
- • HTTP SSE Transport for MCP servers
- • Multi-LLM support (OpenAI, Claude, Azure)
- • Rich assertions & variance testing
- • Detailed JSONL trace logs
Analysis & Reporting
- • Trend analysis & LLM comparison
- • HTML, JSON, Markdown outputs
- • Custom metrics & KPI tracking
- • Markdown reports for each run
Developer Experience
- • CI-friendly CLI for scheduled runs
- • Snapshot regression detection
- • Interactive HTML reports
- • Multi-agent testing via CLI
Quick Start
Up and running in under a minute.
1. Install
2. Create eval config
servers:
my-server:
transport: "http"
url: "http://localhost:3000/mcp"
agents:
claude:
provider: "anthropic"
model: "claude-haiku-4-5-20251001"
temperature: 0
scenarios:
- id: "basic-test"
agent: "claude"
servers: ["my-server"]
prompt: "Use the tools to complete this task..."
eval:
tool_constraints:
required_tools: ["my_tool"]
response_assertions:
- type: "regex"
pattern: "success|completed" 3. Run evaluation
AI-Powered Tools
Built-in AI assistants to supercharge your workflow.
Scenario Assistant
AI chat to help design and refine evaluation scenarios. Describe what you want to test and get ready-to-use YAML configurations.
Result Assistant
AI chat to analyze and explain completed run results. Understand failures, spot patterns, and get actionable improvement suggestions.
MCP Tool Analysis
Automated review of your MCP tool definitions for quality, safety, and LLM-friendliness. Get recommendations before testing.
Agent Workflows
Use MCPLab with LLM agents
Install the `mcplab-assistant` skill and reuse the same prompts across Claude, OpenAI Codex, and similar coding agents.
Install the skill once
Use the Skills CLI installation flow documented in the MCPLab docs.
Prompt examples for any LLM agent
These prompts are agent-neutral and work as reusable starting points.
Generate a minimal, valid starter config before scaling up scenarios and agents.
Run one config across multiple agents and summarize performance differences clearly.
Analyze run artifacts and return concrete fixes tied to failed scenarios.
Documentation
Everything you need to go from setup to deeper analysis
Start quickly, then dive deeper with guides for setup, scenario design, app workflows, debugging, and advanced evaluation analysis.